〇まとめ

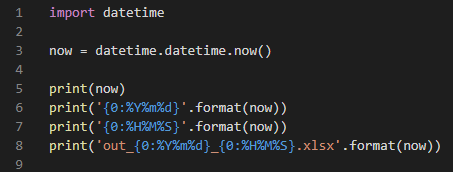
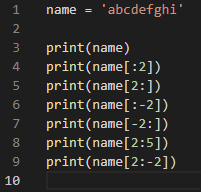
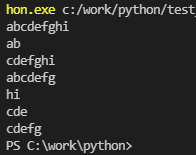
N = ‘6 4 9 12 3 7’
print(N)
NL = N.split()
print(NL)
print(NL[0])
print(type(NL[0]))
L = ‘6, 4, 9, 12, 3, 7’
print(L)
LL = L.split(‘,’)
print(LL)
for i in range(6):
LL[i] = int(LL[i])
print(LL)
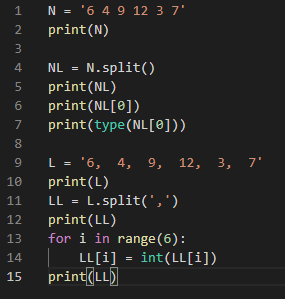

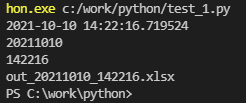
6 4 9 12 3 7
[‘6’, ‘4’, ‘9’, ’12’, ‘3’, ‘7’]
6
<class ‘str’>
6, 4, 9, 12, 3, 7
[‘6’, ‘ 4’, ‘ 9’, ‘ 12’, ‘ 3’, ‘ 7’]
[6, 4, 9, 12, 3, 7]
〇詳細
Nを「6 4 9 12 3 7」という文字列とします。
N = ‘6 4 9 12 3 7’
print(N)
# 6 4 9 12 3 7
spilt を使って、文字列を分割出来ます。
引数を省略した場合、デフォルトでは空白で分割される
NL = N.split()
print(NL)
# [‘6’, ‘4’, ‘9’, ’12’, ‘3’, ‘7’]
分割した文字列は、リスト型になる。
リストの先頭は「6」となるが、数値ではなく文字のまま。
数値への変換は後述。
print(NL[0])
# 6
print(type(NL[0]))
# <class ‘str’>
今度は、「,」で区切られた数値を文字列とします。
L = ‘6, 4, 9, 12, 3, 7’
print(L)
# 6, 4, 9, 12, 3, 7
文字列にあわせて、今回は「,」で文字列を分割します。
分割後は前回同様文字です。
LL = L.split(‘,’)
print(LL)
# [‘6’, ‘ 4’, ‘ 9’, ‘ 12’, ‘ 3’, ‘ 7’]
以下のようにして、各文字列を数値に変換できます。(各文字が整数の場合)
for i in range(6):
LL[i] = int(LL[i])
print(LL)
# [6, 4, 9, 12, 3, 7]

|
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/18d04d2e.45716db2.18d04d2f.629879a7/?me_id=1213310&item_id=18843211&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F3193%2F9784798153193.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")